
What’s in a strain, and how do we know?
Last Friday, May 20th, the scientific journal PLOSone published an article titled “The phytochemical diversity of commercial Cannabis in the United States” in which the authors describe their analysis of over 90,000 cannabis test results, asking the critical question: what’s in a strain? Confidence Analytics contributed to the research paper by providing anonymized data about cannabinoids and terpenes to the authors.
Authors Christiana J. Smith and Nick Jikomes are, or have been, affiliated with Leafly, a popular consumer-oriented website focused on cannabis use and education. Along with co-authors Daniela Vergara and Brian Keegan from the University of Colorado, the authors describe a sophisticated machine learning technique (aka “statistics”) they used to analyze thousands of test results from six US-based cannabis labs, including Confidence.
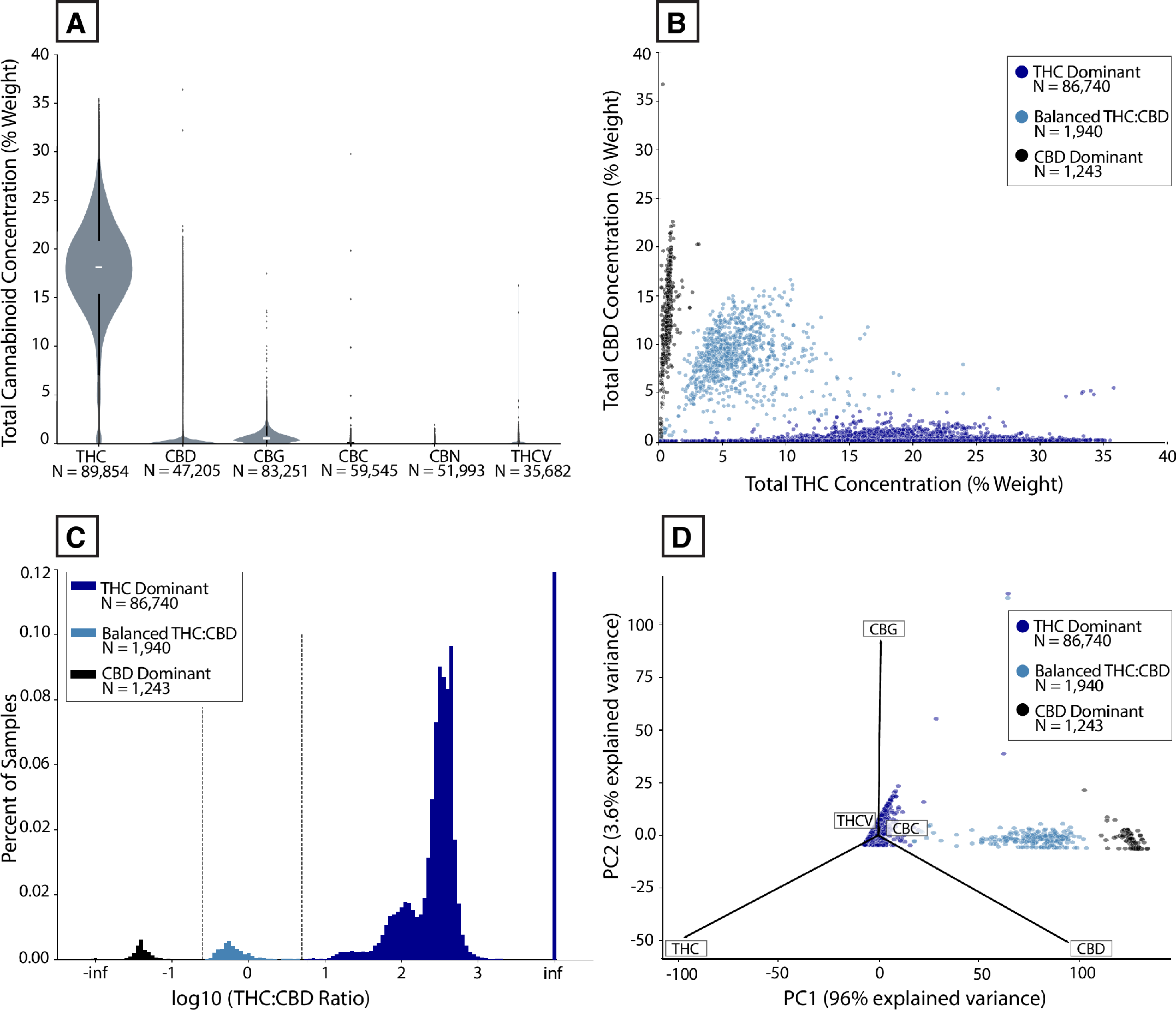
Notably, the findings appear to “debunk” the popular “indica-sativa-hybrid” model commonly used for strain categorization. Instead, the authors found that cannabis strains can, and probably should, be categorized based on chemical composition. If we believe that different strains of cannabis have different effects on the user, then those differences in effect must be the result of differences in chemical composition. The authors demonstrate that different strains of cannabis do indeed have different chemical compositions, and that these chemical compositions are repeatable between geographies and through time when the strains are of common lineage. Furthermore, the diversity of strains appear to be “clustered” based on their chemical compositions whereby strains in the same cluster are more similar to each other than they are to strains in a different cluster. The results of the study indicate there are more than three such clusters among THC-dominant strains, and the clusters do not align well with the common categorizations of indica-sativa-hybrid.
To categorize a strain, you must first know what’s in a strain.
This is exciting research, immediately applicable to consumer and cultivator decision making. Knowing why some strains are similar to others, and which strains, may help growers maintain a diverse product line, and may also help consumers identify strains, or groupings of strains, that they prefer based on similarity.
Importantly, this article in PLOSone references a previous publication in nature where the authors detail the unfortunate fact that while test results from cannabis labs can provide useful information about the chemical compositions of strains, many labs are not collecting data with enough precision or accuracy to make such meaningful inferences. We’ve discussed those implications on our blog before.